 Minotauromaquia
Minotauromaquia
Services Web d'Amazon (AWS), et en particulier le service de stockage simple (S3)[1] sont largement utilisés par de nombreuses personnes et entreprises pour gérer leurs données, sites Web et backends. Celles-ci vont de personnes isolées et de petites startups à des sociétés d’évaluation de plusieurs milliards de dollars telles que Pinterest.[2] et (anciennement) Dropbox.[3] Cette page n'est pas destinée à servir de guide pour l'intégration de S3; vous pouvez trouver beaucoup d'autres guides similaires en ligne.[4] Il vise plutôt les particuliers et les entreprises dont les coûts S3 prévus se situent entre 10 dollars par mois et 10 000 dollars par mois. D'autres listes similaires de conseils sont disponibles en ligne.[5]
Cette page ne rentre pas non plus dans d’autres types d’optimisations S3, telles que l’optimisation des noms de compartiment, de dossier et de fichier et de l’ordre des opérations, qui visent à optimiser le débit ou à réduire la latence. La plupart de ces optimisations n'affectent pas les coûts directement (de manière positive ou négative). De plus, ils ne sont généralement pertinents qu'à une échelle beaucoup plus grande que celle à laquelle le public cible de cette page est susceptible d'être. Vous pouvez en savoir plus sur ces optimisations dans le guide officiel S3[6] et ailleurs.[7]
Première partie de six:
Acquérir une compréhension globale de S3
- 1 Comprenez votre cas d'utilisation S3. S3 peut être utilisé pour de nombreux objectifs.
- En tant que lieu de stockage de fichiers pour une diffusion en direct sur des sites Web, y compris des fichiers image[8] ou un site Web statique entier (généralement derrière un CDN tel qu'Amazon CloudFront ou CloudFlare).[9][10]
- En tant que "lac de données", lieu où vous utilisez ou générez des données dans vos applications: S3 devient essentiellement le stockage à long terme de vos données, vos données initiales générées étant consignées sur S3, et diverses applications lisant depuis S3. , en transformant les données et en écrivant à S3.[11][12][13]
- En tant qu '"entrepôt de données", un lieu de stockage de sauvegardes à long terme de données structurées et non structurées non destinées à une consommation active ultérieure.
- Pour stocker les exécutables, les scripts et les configurations nécessaires au lancement de nouvelles instances EC2 avec vos applications (ou mettre à jour vos applications sur des instances existantes).
- 2 Comprendre la principale façon dont S3 affecte les coûts. Les nombres ci-dessous sont pour le stockage standard, les avertissements associés aux autres formes de stockage sont discutés plus tard.[14] Tous les coûts sont appliqués et déclarés séparément pour chaque seau et chaque heure; En d'autres termes, si vous téléchargez votre rapport de facturation détaillé, vous verrez un élément de ligne pour chaque combinaison de compartiment, heure et type de coût.
- Frais de stockage: Le coût est mesuré dans l'espace de stockage multiplié par le temps. Vous ne payez pas d'avance pour un espace de stockage alloué. Au contraire, chaque fois que vous utilisez plus d'espace de stockage, vous payez un supplément pour ce stockage supplémentaire pendant la durée d'utilisation. Les coûts peuvent donc varier avec le temps, à mesure que la quantité de données stockées a changé. Les coûts de stockage sont indiqués séparément pour chaque seau toutes les heures. La tarification varie selon les régions mais est fixée dans chaque région. En décembre 2016, le coût allait de 2,3 cents par mois-Go en norme américaine (Virginie du Nord) à 4,05 cents par mois-Go à Sao Paulo.[14]
- Demande de prix: Pour le stockage standard, le coût des demandes PUT, COPY, POST ou LIST varie de 0,005 $ pour 1 000 demandes dans les régions des États-Unis à 0,007 $ pour 1 000 demandes à Sao Paulo.[14] Le coût du GET et de toutes les autres demandes est inférieur d’un ordre de grandeur, allant de 0,004 dollar pour 10000 demandes dans toutes les régions des États-Unis à 0,0056 dollar pour 10 000 demandes. Notez toutefois que la plupart des coûts associés à une demande GET sont pris en compte dans les coûts de transfert de données (si la demande provient de l'extérieur de la région). Notez également que pour les données stockées dans d'autres types de stockage, le prix demandé est un peu plus élevé. Un autre type de demande qui devient pertinent lors de la discussion des politiques de cycle de vie est la demande de transition du cycle de vie (par exemple, la transition d'un stockage standard vers un stockage IA ou Glacier).
- Frais de transfert de donnéesLes coûts sont nuls dans la même région AWS (à la fois S3 -> S3 et S3 -> instances EC2), environ 2 centimes par Go pour le transfert de données entre régions et environ 9 centimes par Go pour le transfert de données hors AWS.
- Tarification de récupération: Cela ne s'applique pas au stockage standard, mais s’applique plutôt à deux autres classes de stockage, à savoir IA et Glacier. Ce prix est appliqué par Go pour les données récupérées.
- 3 Comprendre le rôle central joué par les seaux dans l’organisation de vos fichiers S3 et l’utilisation de «objet» pour les fichiers S3.
- Vous pouvez créer des compartiments sous votre compte. Un compartiment est identifié par une chaîne (le nom du compartiment). Il ne peut y avoir qu'un seul compartiment avec un nom de compartiment donné sur l'ensemble de S3, pour tous les clients; par conséquent, vous ne pourrez peut-être pas utiliser un nom de compartiment si quelqu'un d'autre l'utilise déjà.
- Chaque compartiment est associé à une région AWS et est répliqué sur plusieurs zones de disponibilité au sein de cette région. Les informations sur la zone de disponibilité ne sont pas disponibles pour l'utilisateur final, mais constituent un détail d'implémentation interne qui aide S3 à maintenir une durabilité et une disponibilité élevées des données.
- Dans chaque compartiment, vous pouvez stocker vos fichiers directement sous le compartiment ou dans des dossiers. Il n'est pas nécessaire de créer ou de supprimer des dossiers. Si vous enregistrez un fichier, il créera automatiquement des "dossiers" pour le chemin du fichier, s'ils n'existent pas déjà. Une fois qu'il n'y a pas de fichiers en dessous, le dossier cesse automatiquement d'exister.
- La manière dont S3 stocke les informations se présente sous la forme d'un magasin de valeurs-clés: pour chaque préfixe qui n'est pas un nom de fichier, il stocke l'ensemble de fichiers et de dossiers avec ce préfixe. Pour chaque nom de fichier, il le mappe au fichier réel. En particulier, différents fichiers d'un compartiment peuvent être stockés dans des parties très différentes du centre de données.
- S3 appelle ses fichiers "objets", et vous pourriez rencontrer ce terme lors de la lecture de S3 ailleurs.
- 4 Comprendre les différentes manières d'interagir avec les fichiers S3.
- Vous pouvez télécharger et télécharger des fichiers en ligne en vous connectant via un navigateur.
- Les outils de ligne de commande basés sur Python incluent l'interface de ligne de commande AWS,[15], le s3cmd désuet[16] et plus récent s4cmd[17].
- Si vous utilisez Java ou un autre langage basé sur la machine virtuelle Java (Scala, par exemple), vous pouvez accéder aux objets S3 à l'aide du kit SDK Java AWS.[18]
- Les outils de déploiement tels que Ansible et Chef proposent des modules pour gérer les ressources S3.[19]
- 5 Comprendre les avantages et les inconvénients du traitement de S3 et de ses différences avec un système de fichiers traditionnel.
- Avec S3, il faut un peu plus de gymnastique (et de temps d'exécution) pour obtenir une image globale de la quantité de données utilisée dans un compartiment ou dans les sous-dossiers de ce compartiment. En effet, ces données ne sont enregistrées nulle part directement, mais doivent plutôt être calculées via des recherches de valeur-clé récursives.
- La recherche de tous les fichiers correspondant à une expression régulière peut s'avérer très coûteuse, en particulier lorsque cette expression inclut des caractères génériques. au milieu de l'expression plutôt qu'à la fin.
- Il est impossible d'effectuer des opérations telles que l'ajout de données à un fichier: vous devez récupérer le fichier, le modifier, puis sauvegarder tout le fichier modifié (voir plus loin les fonctionnalités de synchronisation).
- Déplacer ou renommer des fichiers implique en réalité la suppression d'objets et la création de nouveaux. Déplacer un dossier implique la suppression et la recréation de tous les objets sous celui-ci. Chaque déplacement de fichier implique un appel GET et un appel PUT, ce qui entraîne une augmentation du prix des demandes. De plus, les objets en mouvement peuvent être coûteux si les objets sont stockés dans des classes de stockage (Standard-IA et Glacier) où la récupération coûte cher.
- S3 peut prendre en charge des fichiers d'une taille maximale de 5 To, mais le transfert de données entre régions peut commencer à être perturbé pour des fichiers de plus de quelques centaines de mégaoctets. La CLI utilise le téléchargement en plusieurs parties pour les fichiers volumineux. Assurez-vous que si vos programmes traitent des fichiers volumineux, ils fonctionnent via le téléchargement en plusieurs parties ou divisent la sortie en fichiers plus petits.
- S3 ne fournit pas un support complet pour rsync. Cependant, il existe une commande sync (aws s3 sync dans l'AWS CLI et s3cmd sync dans s3cmd) qui synchronise tous les contenus entre un dossier local et un dossier S3 ou entre deux dossiers S3. Pour les fichiers qui existent dans le dossier source et le dossier de destination, il peut détecter des fichiers identiques et éviter le transfert de données si les fichiers sont identiques; Cependant, il n'est pas aussi efficace que rsync car il peut nécessiter un transfert complet si les fichiers diffèrent un peu, alors que rsync n'envoie qu'un petit diff pour les fichiers très similaires. L'autre différence avec rsync est qu'il s'applique à un dossier entier et que les noms de fichiers ne peuvent pas être modifiés.
Deuxième partie de six:
Données de compression / compression
- 1 Assurez-vous de compresser les données lorsque cela est autorisé par les exigences de votre application avant de commencer.
- Découvrez les formes de compression et de compression compatibles avec les processus que vous utilisez pour générer des données et les processus que vous utilisez pour lire et traiter les données.
- Assurez-vous d'utiliser la compression et la compression pour vos plus gros volumes de données dans la mesure où cela n'interfère pas avec votre application. En particulier, les journaux d'utilisateurs bruts et les données structurées basées sur l'activité de l'utilisateur sont les principaux candidats à la compression.
- En règle générale, la compression permet d'économiser non seulement sur les coûts de stockage mais aussi sur les coûts de transfert (lors de la lecture / écriture) et peut même accélérer votre application si le temps de téléchargement est plus important que le temps de compression / décompression local. . C'est souvent le cas.
- Pour prendre un exemple en convertissant de gros fichiers de données structurés au format BZ2, l’espace de stockage peut varier de 3 à 10; Cependant, BZ2 nécessite un calcul intensif pour compresser et dézipper. Les autres algorithmes de compression à prendre en compte sont gzip, lz4 et zstd.[5]
- Il existe d'autres moyens possibles de réduire l'espace: utiliser un stockage basé sur des colonnes plutôt que le stockage basé sur des lignes et utiliser des formats binaires (tels que AVRO) plutôt que des formats lisibles par l'homme (tels que JSON) pour conserver les données à long terme.[5]
- 2 Si la compression des données n'est pas possible au moment de la première écriture, envisagez d'exécuter un autre processus pour ré-ingérer et compresser les données. C'est généralement une solution sous-optimale et très rarement nécessaire, mais il peut y avoir des cas où cela est pertinent. Si vous examinez une solution de ce type, vous devez exécuter les calculs avec soin en fonction du coût de réenregistrement et de compression des données et de la durée totale de conservation des données.
Troisième partie de six:
Optimiser les coûts de stockage
- 1 Comprendre les différences entre les quatre types de stockage S3.[14]
- Le stockage standard est le plus coûteux pour le stockage, mais il est le moins cher et le plus rapide pour apporter des modifications aux données. Il est conçu pour une durabilité de 99,999999999% (sur une année, c'est-à-dire la fraction attendue des objets S3 qui survivront sur un an) et une disponibilité de 99,99% (disponibilité relative à la probabilité qu'un objet S3 soit accessible à un moment donné) ). Notez que dans la pratique, il est très rare de perdre des données dans S3, et que les facteurs de risque de perte de données sont plus importants que ceux qui disparaissent de S3 (suppression accidentelle des données et piratage malveillant de votre compte pour supprimer du contenu ou même Amazon étant obligé de supprimer vos données en raison de la pression des gouvernements).[20]
- Le stockage à redondance réduite (RRS) était 20% moins cher que le stockage standard et offre un peu moins de redondance. Vous souhaiterez peut-être l'utiliser pour beaucoup de vos données qui ne sont pas très critiques (comme les journaux d'utilisateurs complets). Ceci est conçu pour une durabilité de 99,99% et une disponibilité de 99,99%. Cependant, en décembre 2016, les réductions de prix effectuées sur le stockage standard n'étaient pas accompagnées de réductions de prix correspondantes pour le RRS, de sorte que le RRS est également ou plus cher à l'heure actuelle.[21][22]
- Stockage standard - L 'accès non fréquent (appelé S3 - IA) est une option introduite par Amazon en septembre 2015, qui combine la durabilité élevée de S3 avec une faible disponibilité de seulement 99%. C'est une option pour stocker des archives à long terme qui ne nécessitent pas souvent un accès, mais qui, lorsqu'elles doivent être accessibles, doivent être rapidement accessibles.[23] S3 - IA est facturé pour un minimum de 30 jours (même si les objets sont supprimés avant cela) et pour une taille minimale de 128 Ko. Il est environ deux fois moins cher que S3, bien que la remise précise varie selon les régions.
- Le glacier est la forme de stockage la moins chère. Cependant, Glacier coûte de l'argent à désarchiver et rend à nouveau disponible pour la lecture et l'écriture, avec le montant que vous devez payer en fonction du nombre de demandes de récupération, de la rapidité avec laquelle vous souhaitez récupérer les données et de la taille des données récupérées. De plus, les fichiers Glacier ont une période de stockage minimale de 90 jours: les fichiers supprimés avant cette date sont facturés pour le reste des 90 jours après la suppression.
- 2 Découvrez comment vos coûts augmentent.
- Dans un cas d'utilisation où vous avez un ensemble fixe de fichiers que vous mettez régulièrement à jour (en supprimant efficacement les anciennes versions), vos coûts de stockage mensuels sont à peu près constants, avec une limite supérieure assez étroite. Vos dépenses de stockage cumulatives augmentent linéairement. Ceci est un scénario typique pour un ensemble d'exécutables et de scripts.
- Dans un cas d'utilisation où vous générez continuellement de nouvelles données à un taux constant, vos coûts de stockage mensuels augmentent de manière linéaire. Votre coût de stockage cumulé augmente de manière quadratique.
- Dans un cas d'utilisation où le taux de génération de données augmente de manière linéaire, vos coûts de stockage mensuels augmentent de manière quadratique et votre coût de stockage cumulé augmente de manière cubique.
- Dans un cas d'utilisation où le taux de génération de données augmente de manière exponentielle, votre coût de stockage de données mensuel et votre coût de stockage de données cumulé augmentent également de manière exponentielle.
- 3 Découvrez si la gestion des versions des objets est adaptée à vos objectifs.[24]
- Le contrôle de version des objets vous permet de conserver les anciennes versions d'un fichier. Un avantage est que vous pouvez revoir une version plus ancienne.
- Lorsque vous utilisez le contrôle de version d'objet, vous pouvez le combiner avec les règles de cycle de vie pour supprimer les versions antérieures à un certain âge (voire la version actuelle).
- Si vous utilisez le contrôle de version des objets, gardez à l'esprit que le simple fait de lister les fichiers (en utilisant aws s3 ls ou l'interface en ligne) vous fera sous-estimer le stockage total utilisé, car les anciennes versions ne figurent pas dans la liste.
- 4 Explorez les politiques de cycle de vie pour vos données.
- Vous pouvez définir des stratégies pour supprimer automatiquement des données dans des compartiments particuliers, ou même avec des préfixes spécifiques dans des compartiments, ce qui est plus qu'un certain nombre de jours. Cela peut vous aider à mieux contrôler vos coûts S3 et à vous conformer aux diverses politiques de confidentialité et de données. Notez que certaines lois et politiques de conservation des données pourraient exiger vous maintenez les données pendant une durée minimale; Celles-ci limitent la durée après laquelle vous pouvez supprimer des données dans votre politique de cycle de vie. D'autres politiques ou lois peuvent vous obliger à supprimer des données dans un certain délai; ceux-ci placent une limite supérieure à l'heure après laquelle vous devez supprimer des données dans votre politique de cycle de vie.
- Avec une politique de cycle de vie pour la suppression, la façon dont vos coûts augmentent augmente beaucoup. Maintenant, avec un flux constant de données entrantes, vos coûts de stockage mensuels restent constants plutôt que de croître linéairement, puisque vous stockez uniquement une fenêtre mobile de données plutôt que toutes les données. Même si la taille des données entrantes augmente de manière linéaire, vos coûts de stockage mensuels augmentent uniquement de manière linéaire plutôt que quadratique. Cela peut vous aider à associer vos coûts d'infrastructure à votre modèle de revenus: si votre revenu mensuel est à peu près proportionnel au taux auquel vous recevez des données, votre modèle de stockage est évolutif.
- Une limitation technique: vous ne pouvez pas définir deux stratégies avec le même compartiment où un préfixe est un sous-ensemble de l'autre. Gardez cela à l'esprit lorsque vous réfléchissez à la manière de stocker vos données S3.
- Outre les règles de cycle de vie pour la suppression, vous pouvez également définir des règles pour archiver les données (c.-à-d. Les convertir du stockage standard au système Glacier), réduisant ainsi les coûts de stockage. Cependant, Glacier a une période de rétention minimale de 90 jours: vous êtes facturé pour 90 jours de stockage dans Glacier, même si vous choisissez de le supprimer avant cette date. Par conséquent, si vous avez l'intention de supprimer sous peu, ce n'est probablement pas une bonne idée de passer à Glacier.
- Vous pouvez également avoir une politique de cycle de vie pour convertir les données dans S3 (stockage standard) en S3-IA. Cette stratégie est idéale pour les données auxquelles vous vous attendez fréquemment au lendemain de sa création, mais rarement par la suite. Les fichiers dans IA ont une taille d'objet minimale (vous êtes facturé pour une taille de fichier de 128 Ko pour les fichiers plus petits) et une période de rétention minimale de 30 jours.
- Notez que les transitions du cycle de vie elles-mêmes coûtent de l'argent et qu'il est souvent préférable de créer des objets directement dans la classe de stockage souhaitée plutôt que de les transférer. Vous devrez faire les calculs pour votre cas d'utilisation afin de savoir si et quand la transition du cycle de vie a un sens.
- 5 Utilisez l'heuristique suivante pour déterminer la meilleure classe de stockage en fonction de votre cas d'utilisation. Alors que nous parlons comme si nous traitions avec un seul fichier, nous pensons vraiment à une configuration où cela se produit séparément et indépendamment pour un grand nombre de fichiers.
- La première étape pour déterminer la classe de stockage appropriée consiste à obtenir une estimation de la taille de votre fichier, de la période de rétention, du nombre d'accès souhaité (ainsi que de la variation de ce nombre en fonction de l'âge) et du temps d'attente maximal. lorsque vous avez besoin d'accéder à quelque chose. Vous pouvez utiliser tous ces paramètres comme paramètres dans une formule qui calcule le coût attendu de l'utilisation de chaque classe de stockage. La formule devient plutôt compliquée.
- Notez que les seuils exacts pour ceux-ci peuvent varier en fonction des prix actuels dans votre région. Les prix varient selon les régions et continuent de changer avec le temps. En particulier, les points suivants: prix de stockage pour chaque classe de stockage, demande de prix pour chaque classe de stockage, tarification de récupération pour chaque classe de stockage et exigences de taille minimale et de durée de conservation minimale. Avec ces mises en garde, les heuristiques sont ci-dessous.
- Si vous prévoyez de conserver les données pendant deux semaines ou moins, le stockage standard est préférable à la fois au stockage IA et au stockage Glacier. La raison en est que les durées de conservation minimales (30 jours pour IA, 90 jours pour Glacier) annulent les avantages en termes de coûts (au plus deux fois plus pour IA, environ six fois pour Glacier) à deux semaines ou moins.
- Si la taille de votre fichier est de 64 Ko ou moins, le stockage standard dépasse toujours le stockage IA. En effet, l'exigence de taille minimale de IA (128 Ko) annule l'avantage de coût (au plus le double).
- Si vous souhaitez accéder à chaque fichier une fois par mois ou plus fréquemment, le stockage standard gagne par rapport à IA et à Glacier. C'est parce que le coût supplémentaire d'une seule récupération de données détruit les économies de stockage mensuelles.
- Supposons que vous ayez des données à conserver dans un stockage standard pendant un mois, après quoi vous pouvez les transférer dans IA pendant un mois ou plus, car vous ne pourrez plus avoir besoin d'y accéder par la suite. Il est logique de le transférer dans IA uniquement si le nombre total de mégaoctets-mois dans l'état IA par fichier est d'au moins 1. Les économies devraient permettre de réduire le coût de la transition du cycle de vie du passage à IA. Par exemple, si vous souhaitez conserver les données pendant un mois supplémentaire, la taille du fichier doit être d'au moins 1 Mo pour que cela représente une dépense utile. Notez que la période minimum de 30 jours rend les transitions pour des durées plus courtes encore moins intéressantes.
- De même, pour la migration vers Glacier, le seuil de rentabilité est d’environ 2,5 mégaoctets par mois pour chaque fichier. Notez, cependant, que la période de conservation minimale de 90 jours dans Glacier complique les choses; Si vous souhaitez transférer des données vers Glacier pendant un mois, la taille du fichier doit être supérieure ou égale à 7,5 Mo.
- Si vous ne souhaitez pas accéder au contenu après l'avoir écrit sur S3, la stratégie optimale est généralement standard ou Glacier, le compromis dépendant de la période de rétention. Cependant, il y a un point idéal entre où IA est la meilleure option (par exemple, stocker 128 Ko pendant un mois). Pour illustrer cela, voici une image pour le cas simple où vous devez garder un seul fichier d'un fichier fixe. taille pour une durée déterminée, avec aucun accès attendu après son stockage. La durée en mois est sur l'axe horizontal et la taille du fichier en Go sur l'axe des y. Un point est coloré en bleu, rouge ou jaune selon que la classe de stockage optimale d'un point de vue des coûts est standard, IA ou Glacier. Nous utilisons les coûts comme dans la région américaine standard en décembre 2016.
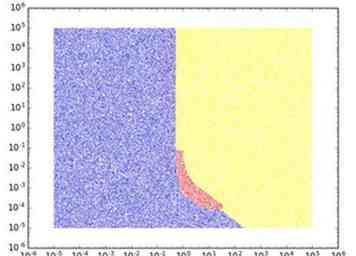
- Lorsque vous augmentez le nombre attendu d’accès aux données, le standard devient optimal pour de plus en plus de cas d’utilisation (c’est-à-dire pour des tailles de données plus importantes et pour des périodes de conservation plus longues). IA commence également à devenir optimale dans les cas où Glacier aurait été précédemment optimal. En d'autres termes, le standard prend le relais de IA et IA prend le relais de Glacier.
- 6 Utilisez les tests d'évaluation de bon sens suivants basés sur votre cas d'utilisation du stockage. Cela vous aidera à avoir une idée des coûts de stockage.
- Si vous diffusez en direct un site Web ou des images statiques: les coûts de stockage seront probablement de quelques centimes, avec des détails dépendant de la taille de votre site. Les coûts principaux de la desserte d’un site en direct sont les coûts de demande et de transfert.
- Si vous stockez un lac de données avec le flux principal généré par l’utilisateur comme activité Web ou d’application (c.-à-d. Journaux de requêtes Web): une ligne de journal de demandes Web individuelle peut varier de 1 Ko (si vous conservez tous les en-têtes standard et champs) à 10 Ko (si vous incluez également des informations sur les périphériques concernant l'utilisateur et le contexte). Si vous recevez un million de requêtes Web par mois et conservez les anciens journaux de requêtes Web pendant un mois, cela représente entre 1 Go et 10 Go de stockage, ce qui représente entre 2,3 cents et 40,5 cents par mois de stockage. Le coût évolue linéairement à la fois avec votre trafic et avec votre décision sur la durée de stockage. Par exemple, avec un milliard de requêtes Web par mois et le stockage de données pendant un an, votre coût mensuel de stockage de données se situe entre 276 et 4860 dollars. L'utilisation de formats binaires et la compression / compression peuvent réduire les coûts.
- Si vous stockez des archives d'images et de séquences vidéo: Par exemple, si vous êtes un réseau de télévision qui prend des images régulièrement et qui souhaite conserver des archives d'anciens métrages disponibles au cas où cela deviendrait pertinent plus tard. C'est un cas d'utilisation où l'espace total de stockage peut être assez important. Par exemple, avec 10 heures de séquences vidéo quotidiennes, vous pourriez ajouter quelque chose de l'ordre de 100 Go (non compressé) chaque jour. Si vous stockez ce métrage dans un stockage standard pour la première année, puis archivez-le dans Glacier pendant neuf ans, le total de vos données atteindra 365 To (36,5 To de stockage standard) et vos coûts de stockage mensuels S3 (avant compression) seront d'environ 2200 $ (deux tiers pour Glacier, un tiers pour le stockage standard). Des compressions de différentes natures peuvent réduire les coûts de stockage d'un facteur allant de 2 à 10.
- Il est instructif de regarder les factures de certains utilisateurs de S3 Power pour avoir une idée de la variation possible d'une facture.
- Dropbox aurait 500 pétaoctets de données dans S3 avant de le transférer sur ses propres serveurs.[25] Aux prix actuels cotés en ligne, cela coûterait environ 10,5 millions de dollars par mois.Bien que Dropbox ait probablement bénéficié d'une remise importante et ait tiré parti de la déduplication et de la compression des données, sa facture était probablement encore d'au moins des centaines de milliers de dollars par mois.
- Un autre exemple extrême de grand utilisateur est DigitalGlobe, qui déplace 100 PB d'images satellitaires à haute résolution vers S3.[26]
- Pinterest a indiqué qu'il ajoutait 20 téraoctets de données par jour, ce qui, dans le stockage standard, signifie que sa facture mensuelle augmenterait de 600 $ / mois chaque jour. Si ce taux d’ajout de données se poursuit pendant dix ans, leur stockage total serait d’environ 75 milliards de dollars et leur facture mensuelle serait de l’ordre de plusieurs centaines de milliers de dollars.
- Au-delà de ces cas d'utilisation extrêmes, même certaines des plus grandes entreprises du monde ont des factures S3 relativement faibles. Par exemple, à la fin de 2013, Airbnb a signalé avoir 50 To de données de photos à haute résolution, ce qui coûterait environ 1150 dollars par mois aux prix actuels.[27]

Partie quatre de six:
Optimisation des coûts de transfert de données
- 1 Si vous utilisez S3 pour un contenu en direct, placez-le derrière un CDN tel que Amazon CloudFront, CloudFlare ou MaxCDN.
- Le CDN possède un grand nombre de sites périphériques dans différentes parties du monde, allant généralement de dizaines à des centaines.
- La demande de l'utilisateur pour la page est acheminée vers l'emplacement du CDN le plus proche. Cet emplacement de bord vérifie ensuite s'il possède une copie mise à jour de la ressource. Sinon, il le récupère depuis S3. Sinon, il sert la copie qu'il a.
- Le résultat: les utilisateurs finaux voient une disponibilité plus élevée et une latence plus faible (car les ressources sont servies à partir d'un emplacement physique près d'eux) et le nombre de demandes et le volume de transfert de données depuis S3 restent faibles. Explicitement, le nombre de requêtes est limité par (nombre d'emplacements périphériques) X (nombre de fichiers) si vous ne mettez jamais à jour les fichiers; Si vous mettez à jour des fichiers, vous devez également les multiplier par le nombre de mises à jour de fichiers.
- 2 Comprendre le principal avantage de la co-implantation de EC2 / S3. Si votre utilisation principale pour S3 est de lire et d’écrire des données dans des instances EC2 (c’est-à-dire tout cas d’utilisation autre que l’instance de diffusion en direct), cet avantage est le meilleur si votre compartiment S3 se trouve dans la même région AWS que EC2 instances qui lisent ou écrivent. Cela aura plusieurs avantages:
- Faible latence (moins d'une seconde)
- Bande passante élevée (supérieure à 100 Mbit / seconde): Notez que la bande passante est en fait assez bonne entre les différentes régions des États-Unis. Ce n'est donc pas un problème important si toutes vos régions se trouvent aux États-Unis. UE, UE et Asie-Pacifique, ou États-Unis et Asie-Pacifique.
- Pas de frais de transfert de données (cependant, vous payez toujours la demande de prix)[14]
- 3 Déterminez l'emplacement (région AWS) de votre ou vos compartiments S3.
- Si vous exécutez des instances EC2 qui lisent ou écrivent sur les compartiments S3: Comme indiqué à l'étape 1, la colocation de S3 et EC2, dans la mesure du possible, facilite la bande passante, la latence et les coûts de transfert de données. Par conséquent, une considération importante dans la localisation de votre compartiment S3 est la suivante: où prévoyez-vous d'avoir les instances EC2 qui interagiront avec ce compartiment S3? Si les instances EC2 sont principalement des instances dorsales, vous devez alors prendre en compte les coûts de ces instances. S'il s'agit d'instances frontales, déterminez les régions dans lesquelles vous prévoyez d'obtenir l'essentiel de votre trafic. De manière générale, vous devez vous attendre à ce que les considérations d’instance EC2 soient plus importantes que les considérations S3 pour déterminer la région. Donc, il est généralement judicieux de décider d’où vous voulez que votre instance EC2 soit capable de fonctionner, puis d’y installer vos compartiments S3. En général, les coûts S3 sont inférieurs dans les mêmes régions que les instances EC2, ce qui, heureusement, ne crée pas de conflit.
- S'il existe d'autres services AWS que vous devez posséder, mais qui ne sont pas disponibles dans toutes les régions, cela peut également limiter votre choix de région.
- Si vous téléchargez fréquemment des fichiers de votre ordinateur personnel vers S3, vous pouvez envisager de placer un compartiment dans une région plus proche de chez vous pour améliorer la latence de téléchargement. Cependant, cela devrait être une considération mineure par rapport aux autres.
- Si vous prévoyez d'utiliser S3 pour les images statiques en direct, choisissez l'emplacement en fonction de l'endroit où vous prévoyez d'obtenir votre trafic.
- Dans certains cas, les règles que vous êtes tenu de respecter en vertu de la loi ou d'un contrat limitent votre choix de région pour le stockage de données S3. Gardez également à l'esprit que l'emplacement physique de votre compartiment S3 pourrait affecter ce que les gouvernements peuvent légalement obliger Amazon à publier vos données (bien que ces événements soient assez rares).[28]
- 4 Déterminez si la réplication inter-régions est appropriée pour votre compartiment.[29] La réplication inter-régions entre les compartiments de différentes régions synchronise automatiquement les mises à jour des données dans un compartiment avec les données des autres compartiments. Le changement peut ne pas se produire immédiatement, et les modifications importantes des fichiers en particulier sont limitées par les limitations de bande passante entre les régions. Gardez à l'esprit les avantages et inconvénients suivants de la réplication inter-régions.[5]
- Vous payez plus en coûts de stockage S3, car les mêmes données sont mises en miroir dans plusieurs régions.
- Vous payez en S3 <-> S3 coûts de transfert de données. Toutefois, si les données sont lues ou écrites par des instances EC2 dans plusieurs régions, cela peut être compensé par des économies dans les coûts de transfert de données S3 -> EC2. La principale méthode que vous pouvez utiliser est de charger les mêmes données S3 dans des instances EC2 dans de nombreuses régions différentes. Par exemple, supposons que vous ayez 100 instances chacune dans l’est et l’ouest des États-Unis où vous devez charger les mêmes données à partir d’un compartiment S3 dans l’ouest des États-Unis. Si vous ne répliquez pas ce compartiment dans les États-Unis, vous payez le coût de transfert des 100 transferts de données du compartiment S3 aux machines US East. Si vous répliquez le compartiment dans l'est des États-Unis, vous ne payez qu'une seule fois pour les coûts de transfert de données.
- La réplication interrégionale a donc beaucoup de sens pour les exécutables, les scripts et les données relativement statiques, où vous accordez une grande importance à la redondance interrégionale, où les mises à jour des données sont rares et où le transfert de données se fait principalement dans S3 -> EC2. direction. Un autre avantage est que si ces données sont répliquées à travers les régions, il est beaucoup plus rapide de créer de nouvelles instances, ce qui permet des architectures d'instance EC2 plus flexibles.
- Pour les applications de journalisation (où les données sont lues par de nombreuses instances frontales et doivent être consignées dans un emplacement central dans S3), il est préférable d'utiliser un service tel que Kinesis pour collecter des flux de données entre régions plutôt que d'utiliser des compartiments S3 répliqués entre régions. .
- Si vous utilisez S3 pour la diffusion en direct d'images statiques sur un site Web, la réplication inter-régions peut être utile si le trafic de votre site Web est global et que le chargement rapide des images est important.
- 5 Si vous synchronisez des mises à jour régulières sur des fichiers déjà existants, choisissez une structure de dossiers permettant l'utilisation de la fonction de synchronisation de l'AWS CLI.
- La commande "aws s3 sync" se comporte comme rsync, mais ne peut être exécutée qu'au niveau d'un dossier. Par conséquent, conservez votre structure de dossiers de manière à pouvoir utiliser cette commande.
- 6 Gardez à l'esprit l'heuristique suivante pour estimer les coûts de transfert.
- Pour un site Web statique en direct, le transfert de données mensuel sans CDN est égal à la taille totale du trafic de chaque page visitée (y compris les images et autres ressources chargées sur la page). Par exemple, pour un million de pages vues et une taille de page moyenne de 100 Ko, le total des données est de 100 Go, ce qui coûte 9 dollars par mois.
- Pour un site Web statique hébergé en direct derrière un CDN, le CDN impose une limite supérieure au transfert total de données. Plus précisément, si vous ne mettez pas à jour les données, de sorte que le CDN serve son propre cache, le transfert total de données est limité par le produit de la taille totale de votre site Web et du nombre d'emplacements périphériques du CDN, quel que soit le trafic. le volume. Par exemple, si votre site a un total de 1000 pages de 100 Ko chacune, la taille totale est de 100 Mo. S'il y a 100 emplacements périphériques, cela donne une limite de transfert de données totale de 10 Go par mois ou une limite de coût de 90 cents par mois. Cependant, si vous mettez à jour certains des fichiers, vous devez recompter chaque fichier après chaque mise à jour.
- La mesure dans laquelle les CDN économisent par rapport à l'absence de CDN dépend de la diversité de l'accès à votre contenu et également de la répartition géographique de l'accès. Si vous accédez à votre contenu dans une région géographique, vous économiserez davantage. Si les gens accèdent à un petit nombre de pages sur votre site, vous économiserez davantage. Si, dans chaque région, les gens accèdent à un petit nombre de pages sur votre site (même si les pages diffèrent selon la région), vous économiserez davantage. Les économies de CDN peuvent aller de 50% à 99%.[10]
Cinquième partie de six:
Optimisation des coûts en raison de la demande de prix
- 1 Si le prix demandé est une préoccupation majeure, conservez vos données dans un stockage standard. Voir la partie 3, étape 5 pour plus d'informations.
- 2 Si vous diffusez en direct un site statique ou des images statiques ou des vidéos via S3, placez-le derrière un CDN. C’est pour les mêmes raisons que celles examinées dans la partie 4, étape 1.
- 3 Si vous utilisez S3 comme magasin de données pour la recherche de valeurs-clés, vous devez remplacer le prix des demandes PUT par le prix de transfert de données lorsque vous déterminez la taille des fichiers dans lesquels vous devez partager vos données.
- Si vous partitionnez les données en un grand nombre de petits fichiers, vous devez insérer un grand nombre de fichiers PUT, mais chaque recherche est plus rapide et utilise moins de transfert de données car vous devez lire un fichier plus petit à partir de S3.
- D'un autre côté, si vous partitionnez les données en un petit nombre de fichiers volumineux, vous avez besoin d'un petit nombre de PUT, mais chaque accès coûte cher en transfert de données (car vous devez lire un fichier volumineux).
- Le compromis se produit généralement quelque part au milieu. Mathématiquement, le nombre de fichiers à utiliser correspond à la racine carrée du rapport entre un terme de coût de transfert de données et un terme de coût PUT.
- 4En général, utiliser un plus petit nombre de fichiers de taille moyenne est préférable pour un lac de données.
- 5 Si vous subdivisez les données d'un fichier à l'autre, utilisez un petit nombre de fichiers de taille moyenne (entre 1 Mo et 100 Mo) pour réduire le prix et la surcharge des demandes.
- Un plus petit nombre de fichiers plus volumineux réduit le nombre de requêtes nécessaires pour récupérer et charger les données, ainsi que pour écrire les données.
- Comme il y a une petite quantité de latence associée à chaque lecture de fichier, les processus informatiques distribués (tels que les processus basés sur Hadoop ou Apache Spark) qui lisent les fichiers sont généralement plus rapides avec un petit nombre de fichiers de taille moyenne nombre de petits fichiers.
- Moins votre nombre total de fichiers est élevé, moins il est coûteux d'exécuter des requêtes qui tentent de correspondre à des expressions régulières arbitraires.
- Une mise en garde importante est que, dans de nombreux cas, le type de sortie naturel est un grand nombre de petits fichiers. Cela est vrai pour les sorties des charges de travail de calcul distribué, où chaque nœud du cluster calcule et génère un petit fichier. Cela est également vrai si les données sont écrites en temps réel et que nous souhaitons écrire les données dans un délai très court. Si vous prévoyez de lire et de traiter ces données à plusieurs reprises, envisagez de regrouper les données en fichiers plus volumineux. En outre, pour les données envoyées en temps réel, envisagez d'utiliser des services de diffusion en continu tels que Kinesis pour collecter les données avant de les écrire sur S3.
- 6 Si vous constatez des coûts de demande inattendus importants, recherchez les processus malveillants qui effectuent la correspondance avec les expressions rationnelles. Assurez-vous que toute correspondance avec une regex utilise des caractères génériques aussi proches de la fin du fichier que possible.
- 7 Gardez à l'esprit les heuristiques suivantes pour les coûts de requête.
- Les coûts de demande doivent être compris entre 0% et 20% des coûts de stockage.S'ils sont supérieurs, déterminez si vous utilisez la bonne classe de stockage, partagez les données dans les bonnes tailles ou effectuez des opérations inutiles ou inefficaces. Vérifiez également les transitions inutiles du cycle de vie ainsi que les processus de correspondance des expressions rationnelles non autorisés.
- Les coûts des demandes doivent être inférieurs aux coûts de transfert si vos données sont principalement envoyées à l'extérieur d'AWS (si vos données sont expédiées dans la même région AWS, aucun coût de transfert de données ne sera nécessaire). positif alors que les coûts de transfert seront nuls).
Partie six de six:
Surveillance et débogage
- 1 Configurez la surveillance de vos coûts S3.
- Votre compte AWS a accès aux données de facturation qui fournissent la ventilation complète des coûts. Configurez une alerte de facturation pour que les données commencent à être envoyées à Amazon CloudWatch. Vous pouvez ensuite configurer d'autres alertes à l'aide de CloudWatch.[30] Les données CloudWatch sont fournies sous forme de points de données toutes les quelques heures, mais ne comprennent pas une ventilation détaillée de toutes les dimensions.
- A tout moment, vous pouvez télécharger une ventilation détaillée par heure et par type de service à partir de votre compte root. Ces données sont généralement en retard de 24 à 48 heures, c'est-à-dire que vous ne verrez pas d'informations pour les 24 à 48 heures les plus récentes. Pour S3, vous pouvez télécharger les données au format tableur ou au format CSV en les décomposant par heure, par segment, par région et par type d'opération (GET, POST, LIST, PUT, DELETE, HEADOBJECT ou autres).
- 2 Ecrivez des scripts pour obtenir des rapports quotidiens faciles à lire sur vos coûts de différentes manières.
- Au niveau supérieur, vous pouvez indiquer une ventilation de vos coûts entre le stockage, le transfert et la demande de prix.
- Dans chacun de ces cas, vous souhaiterez peut-être réduire davantage les coûts en fonction de la classe de stockage (Standard, RRS, IA et Glacier).
- Dans le cadre de la tarification des demandes, vous pouvez répartir les coûts selon le type d'opération (GET, POST, LIST, PUT, DELETE, HEADOBJECT ou autres).
- Vous pouvez également fournir une ventilation par compartiment.
- En règle générale, vous devez déterminer le nombre de dimensions que vous explorez en évitant toute compréhension rapide contre une granularité suffisante. Un bon compromis consiste à inclure des analyses détaillées dans une dimension à la fois (une analyse détaillée par compartiment, une analyse détaillée par stockage ou transfert vs demande de prix, une analyse détaillée par classe de stockage) dans votre rapport quotidien si quelque chose semble hors de l'ordinaire.
- 3 Créez un modèle de coût attendu et utilisez votre script pour identifier les écarts entre les coûts réels et votre modèle.
- Sans modèle de coûts devrait être, il est difficile de regarder les coûts et de savoir s’ils ont tort.
- Le processus d'élaboration d'un modèle de coûts est un bon exercice permettant d'articuler clairement votre architecture et de penser à des améliorations, même sans examiner la structure des coûts réels.
- 4 Déboguer des coûts élevés.
- Si le coupable est les coûts de stockage, voir la partie 3.
- Si le coupable est énorme coûts de transfert de données, voir la partie 4.
- Si le coupable est la demande de prix, voir la partie 5.