 Minotauromaquia
Minotauromaquia
Health Level Seven (HL7) est une norme d'interopérabilité utilisée dans les soins de santé. C'est le langage que les systèmes d'information sur la santé utilisent pour communiquer. Par exemple, les services de santé publique ont des registres de vaccination et des systèmes de surveillance syndromique qui doivent communiquer avec les systèmes de dossiers de santé électroniques (DSE) dans les hôpitaux et les cliniques. Ceci est accompli avec les messages HL7. Bien que les normes HL7 aient connu deux révisions majeures depuis HL7 v2, elles restent la norme en matière de soins de santé et la version que vous êtes le plus susceptible de trouver sur le terrain.[1]
Pas
- 1 Apprendre la structure de message HL7. Voici un message HL7 typique avec une coloration syntaxique ajoutée pour identifier plus facilement les éléments d'un message:
- MSH|^~\&|ADT1|MCM|LABADT|MCM|198808181126|SÉCURITÉ|ADT^A01|MSG00001-|P|2.6 EVN|A01|198808181123
PID|||PATID1234^5^M11^^UN||JONES^WILLIAM^UNE^III||19610615|M||2106-3|677 DELAWARE AVENUE^^EVERETT^MA^02149|GL|(919)379-1212|(919)271-3434~(919)277-3114||S||PATID12345001^2^M10^^ACSN|123456789|9-87654^Caroline du Nord
NK1|1|JONES^BARBARA^K|SPO|||||20011105
NK1|1|JONES^MICHAEL^UNE|FTH
PV1|1|je|2000^2012^01||||004777^LEBAUER^Sidney^J.|||Sur||-||ADM|A0
AL1|1||^PÉNICILLINE||CODE16~CODE17~CODE18
AL1|2||^CAT DANDER||CODE257
DG1|001|I9|1550|MAL NEO LIVER, PRIMAIRE|19880501103005|F
PR1|2234|M11|111^CODE151|PROCÉDURES COMMUNES|198809081123
ROL|45^ENREGISTREUR^Liste des rôles principaux|UN D|RO|KATE^FORGERON^ELLEN|199505011201
GT1|1122|1519|FACTURE^PORTES^UNE
EN 1|001|A357|1234|BCMD|||||132987
EN 2|ID1551001|123456789
ROL|45^ENREGISTREUR^Liste des rôles principaux|UN D|RO|KATE^ELLEN|199505011201 - Les messages sont composés de segments, de champs, de composants et de sous-composants. Les segments peuvent être considérés comme des conteneurs regroupant des types de données similaires. Ces données sont contenues dans les champs d'un segment. Les codes à trois caractères en bleu sont les étiquettes de segment pour ce message.
- Chaque segment contient des champs séparés par le bleu clair '|' personnage. Les champs et les segments peuvent être répétés. Les champs répétitifs sont séparés par le caractère rouge "~". Les composants sont les points de données dans les champs et ils sont séparés par le caractère vert '^'. Les sous-composants sont délimités avec le séparateur violet clair «&». Ces caractères spéciaux sont appelés caractères de contrôle. Le tableau suivant contient les caractères de contrôle standard utilisés dans HL7:
-
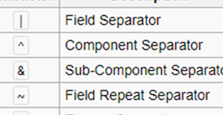
- L'étape suivante consiste à décomposer le message par segment.
- MSH|^~\&|ADT1|MCM|LABADT|MCM|198808181126|SÉCURITÉ|ADT^A01|MSG00001-|P|2.6 EVN|A01|198808181123
-
 2 Brisez le message en segments. Les segments sont les éléments structurels de base à partir desquels les messages HL7 sont générés. Chaque message est composé d'un ou plusieurs segments.
2 Brisez le message en segments. Les segments sont les éléments structurels de base à partir desquels les messages HL7 sont générés. Chaque message est composé d'un ou plusieurs segments. - Le type de message détermine quels segments contiennent un message ainsi que ceux qui sont facultatifs et ceux qui peuvent être répétés. Cette syntaxe est dictée par la version HL7 utilisée pour créer le message. Les segments sont réutilisables dans différents types de messages.
- Les segments de l'exemple de message sont répertoriés dans le tableau suivant:
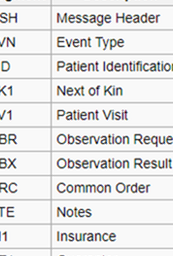
- Ensuite, décomposez les segments en champs.
-
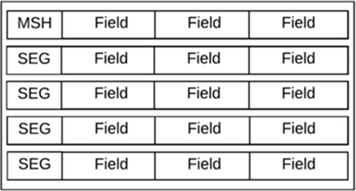 3 Brisez les segments en champs. Le diagramme suivant est un modèle conceptuel d'un message HL7 divisé en segments et en champs. Les codes à trois caractères utilisés au début de chaque segment servent d'étiquettes. Les champs sont notés en étendant le segment pour inclure le numéro d'index du champ. Par exemple, le premier champ de l'en-tête du message serait MSH-1, le second champ serait MSH-2, etc.
3 Brisez les segments en champs. Le diagramme suivant est un modèle conceptuel d'un message HL7 divisé en segments et en champs. Les codes à trois caractères utilisés au début de chaque segment servent d'étiquettes. Les champs sont notés en étendant le segment pour inclure le numéro d'index du champ. Par exemple, le premier champ de l'en-tête du message serait MSH-1, le second champ serait MSH-2, etc. - MSH, l'en-tête du message, est le premier segment de chaque message HL7 et contient des métadonnées de message. Le deuxième segment de chaque message est le segment EVN. Cela contient l'événement que déclenche le message. Dans cet exemple, cet événement est la planification d’une chirurgie en milieu hospitalier.
- Une chose à noter dans l'exemple de message est que tous les champs ne contiennent pas de données. L'extrait suivant du segment NK1 (Next of Kin) contient des champs vides. Les champs vides ici sont indiqués par des séparateurs de champs (|) sans intermédiaire, suivis de la date au format Yymmdd:
- SPO|||||20011105
- Les champs répétés sont séparés par le caractère ~. Cet exemple montre un champ de réaction allergique répété (AL1.5 [1-3]) dans le segment des allergies (AL1):
- CODE16~CODE17~CODE18
- Les champs se subdivisent en composants.
- 4 Brisez les champs en composants. Chaque composant d'un champ est séparé par le caractère ^. Les champs sont notés en étendant la notation des segments par un point décimal suivi du numéro d'index du champ. Le composant d'adresse de rue, par exemple, fait partie du champ d'adresse et peut être indexé avec PID-11.1. PID est le segment d'identification du patient. PID-11.1 est le composant d'adresse de rue du champ d'adresse (PID-11).
- Les composants peuvent être subdivisés en sous-composants en utilisant le caractère & comme séparateur.
- Utilisez le dictionnaire de données HL7 pour rechercher des éléments. Le dictionnaire de données pour tous les éléments contenus dans un message peut être localisé en référençant la norme pour la version de HL7 utilisée pour créer le message.[2] Le numéro de version se trouve dans le champ MSH-12 de tout en-tête de message.
- L'annexe A de la norme contient un dictionnaire de données pour tous les éléments d'un message. Il est disponible dans les formats de fichiers PDF et XLS. Le dictionnaire de données pour HL7 v2.6 est un exemple typique.

 2 Brisez le message en segments. Les segments sont les éléments structurels de base à partir desquels les messages HL7 sont générés. Chaque message est composé d'un ou plusieurs segments.
2 Brisez le message en segments. Les segments sont les éléments structurels de base à partir desquels les messages HL7 sont générés. Chaque message est composé d'un ou plusieurs segments. 
 3 Brisez les segments en champs. Le diagramme suivant est un modèle conceptuel d'un message HL7 divisé en segments et en champs. Les codes à trois caractères utilisés au début de chaque segment servent d'étiquettes. Les champs sont notés en étendant le segment pour inclure le numéro d'index du champ. Par exemple, le premier champ de l'en-tête du message serait MSH-1, le second champ serait MSH-2, etc.
3 Brisez les segments en champs. Le diagramme suivant est un modèle conceptuel d'un message HL7 divisé en segments et en champs. Les codes à trois caractères utilisés au début de chaque segment servent d'étiquettes. Les champs sont notés en étendant le segment pour inclure le numéro d'index du champ. Par exemple, le premier champ de l'en-tête du message serait MSH-1, le second champ serait MSH-2, etc. Facebook
Twitter
Google+